Building a data pipeline with python
animenon |
Description:
A talk about building a data pipeline in python in two ways-
- Using pandas (for usual datasets)
- Using pyspark (for Big data)
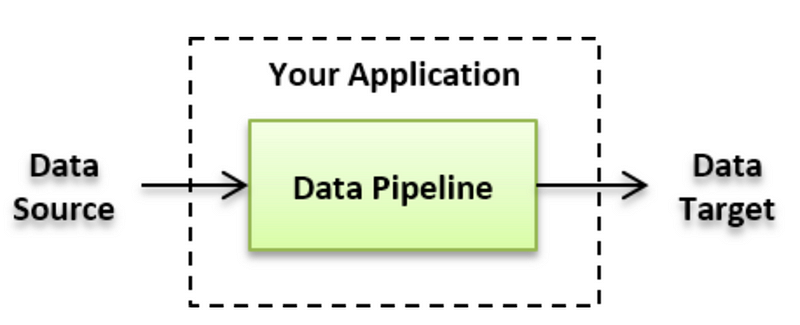
Data pipeline would involve data ingestion, transformation (cleansing, manipulation) and storage. It would also involve deriving insights from this data which I don't intend to cover in this talk.
Pandas Data Pipeline
Intro
Why Pandas? How and When to Use?
Small Demo -
Tools used - pandas module, numpy module
Steps Involved
- Create Pandas DataFrame
- Data Preparation and Transformations (Missing value imputation, Removing outliers and other cleansing tasks)
- Exploratory data analysis
PySpark Data Pipeline
Why Apache Spark? How and When its used?
Small Demo -
Tools used - Apache Spark, Apache Hive
Steps Involved
- Create a Spark DataFrame
- Data Preparation and Transformations (Missing value imputation, Removing outliers and other cleansing tasks)
- Exploratory data analysis
Prerequisites:
- Python
- Data Management basics
Content URLs:
Slides: https://docs.google.com/presentation/d/1iMssWK2V8SPSaXC9dMVtbGbETH3lUADwZ1XH7bulm5A
Speaker Info:
Anirudh has over 3 years of python development experience and has presented talks on Data Engineering and Big Data at many platforms. He has also presented a talk about Natural Language Processing at a Bangalore Python User Group meet in 2015.
Anirudh works as an Asst Manager, Big Data Analytics at Genpact. He designs and builds data pipelines using python and big data tools/technologies.